
Deliberated Domain Bridging for Domain Adaptive Semantic Segmentation
论文:https://arxiv.org/abs/2209.07695
代码:https://github.com/xiaoachen98/DDB
1、引言域自适应语义分割(Domain Adaptive Semantic Segmentation, DASS)旨在利用大量有标注的源域数据和未标注的目标域数据,然后把知识从源域迁移到目标域中。先前的DASS方法大多试图直接把源域学到的知识迁移到目标域中,然而巨大的领域差异往往会限制这些方法的有效性,只能取得次优的性能。为了缓解这个问题,一些方法通过在输入空间(style transfer类方法),或输出空间(self-training类方法)进行域桥接(domain bridging, DB)来在领域间逐渐地迁移知识。
通过前人的实验以及我们自己的复现结果的发现,这些基于style transfer的方法总是会产生一些不利于密集预测的伪影(尤其是在高分辨率场景下)。为了能够在输入空间和输出空间都能够构建中间域,我们求助于一些data mix技术。我们首先把这些data mix技术分为两类,即全局插值(如mix-up)和局部替换(如cutmix)。然后,我们构建了一个简单的自训练pipeline来验证这些DB方法的有效性:
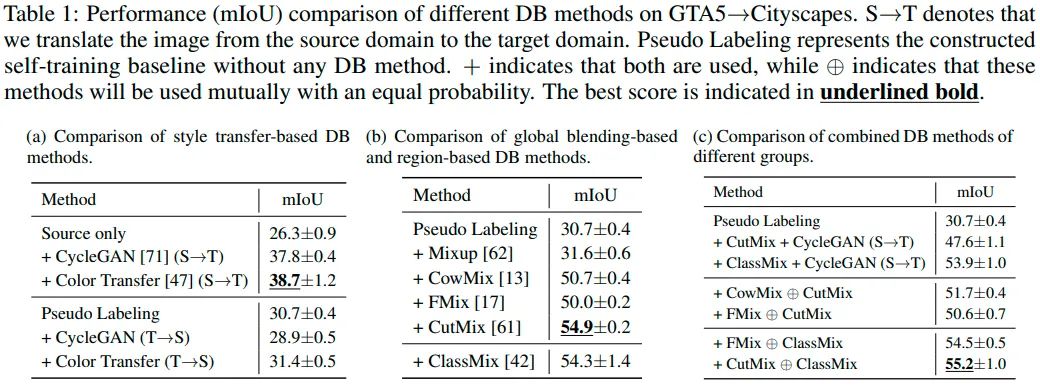
从表1可以发现基于局部替换的DB方法要优于其它类型的DB方法,并且从表1(c)中还可以发现CutMix(region level)和ClassMix(class level)这两个DB技术混合使用可以带来一些性能增益。这个观察引起了我们的注意,于是我们可视化了两个方法训练出的模型特征分布和预测:
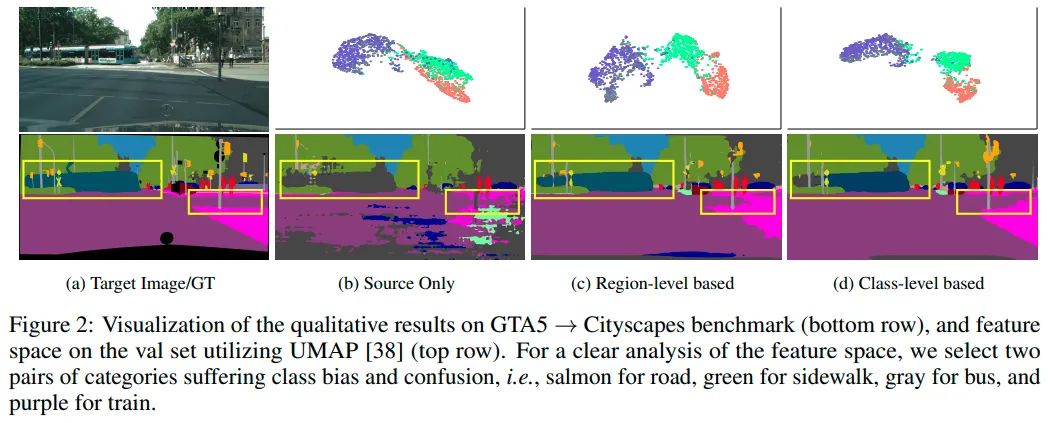
从上图可以发现,region level的 DB方法训练出的模型更关注目标的上下文信息而损害一些特征的可判别性(正确分割出火车类但特征分布比较松散),class level的DB方法训练出的模型则更倾向于挖掘目标自身的特性而忽略了目标的上下文信息(有更紧凑的特征分布但完全混淆了火车和公交车)。这种互补的特性引起了我们的兴趣以及进一步的探究。
2、方法介绍核心思想:充分利用region level的DB方法和class level的DB方法的互补特性,得到更优的性能。
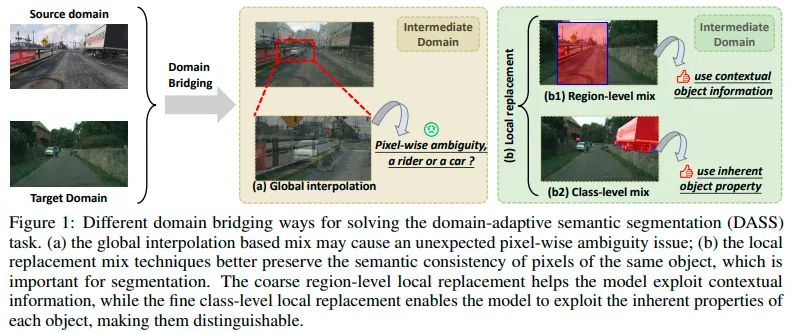
方法流程:概括来说,我们采用了双路径领域桥接(DPDB)步骤和跨路径知识蒸馏(CKD)步骤交替进行的训练策略来取长补短,相互促进。具体来说,我们先用region level DB和class level DB进行自训练,得到两个互补的教师模型(DPDB)。接着各自在目标域上计算出每个类别的prototype用于计算下一步CKD步骤中的ensemble权重图。在CKD步骤中,我们随机初始化一个学生模型,在目标域上用DPDB中得到的两个互补教师模型来进行多教师硬蒸馏,并且每个位置与对应类别的prototype距离会被用来动态加权两个教师模型的预测。通过CKD可以得到优于所有教师模型的学生模型,这个学生模型的权重会用来初始化下一个阶段的DPDB的模型,达到交替训练的目的。算法伪代码如下:

我们的方法除了可应用于标准的单源-单目标的设定外,还不需要任何定制化设计即可在多源-单目标以及单源-多目标的设定上取得优异性能。
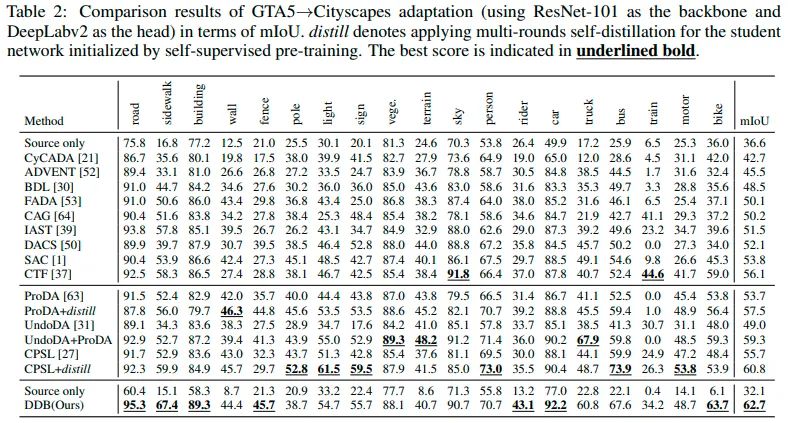
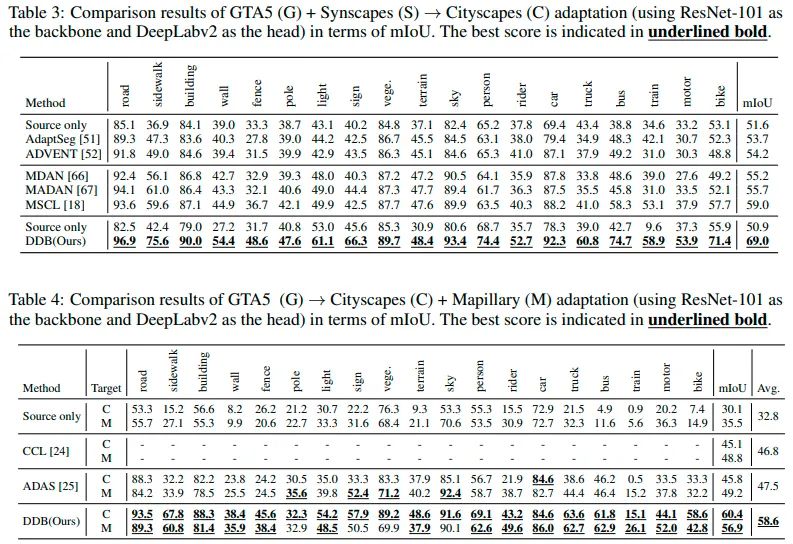
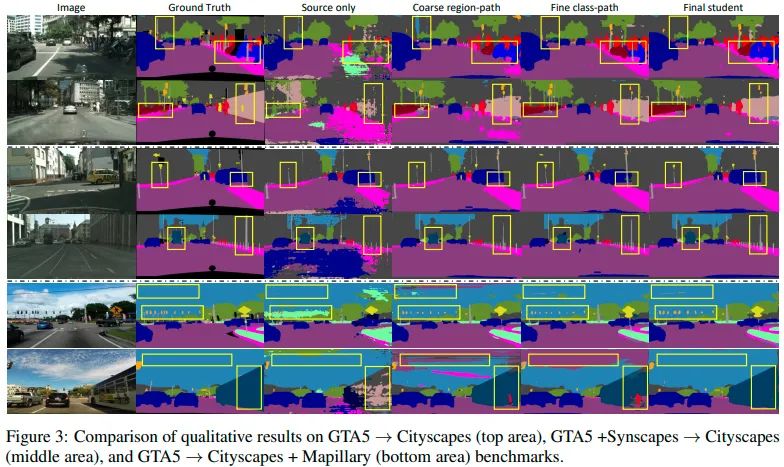
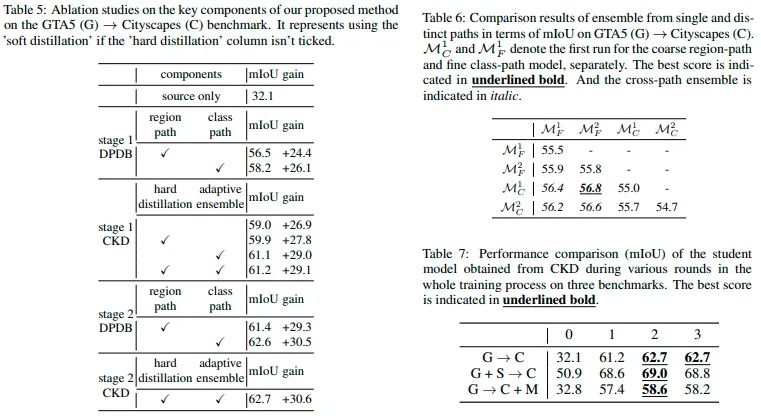
此外,我们还进行了完整的消融实验和互补性实验来验证motivation以及所提策略的有效性。从表5可以发现硬蒸馏,适应性集成,以及交替训练的有效性。从表6可以看出region level DB和class level DB方法的互补性。从图3的预测图中也可以看出两种DB方法的互补性,以及我们提出的DDB可以很好地集成各自的优点,青出于蓝而胜于蓝。
本文简单的介绍了DDB的研究动机,方法介绍和简单实验分析其有效性。论文和补充材料中有更加详细的讨论,并且有更详细的细节描述。希望我们的工作能够给DASS带来一些有意思的见解。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

