VointConv是指对Voint空间上的操作进行卷积运算 。
一个简单的VointConv操作的示例是将共享的多层感知机 ( MLP ) 应用于可见视图特征。
VointNet 模型的目标是:获得可以随后被任何点云处理 pipeline 使用的多视图点云特征。
VointNet 模块 定义如下。
其中 是任意点卷积运算(例如共享 MLP 或 EdgeConv)。在将 VointMax 应用于视图特征以获得点特征之前,VointNet 使用学习到的 VointConv 转换各个视图特征。
用于 3D 点云处理的 VointNet **pipeline ** —— VointNet Pipeline for 3D Point Cloud Processing完整的 pipeline 如图 2 所示。损失可描述如下:
其中 :
要联合学习的权重是 2D 主干 的权重和使用相同 3D 损失的 VointNet 的权重。可以选择添加 上的辅助 2D 损失以在图像级别进行监督。
对于分类,整个对象可以被视为单个 Voint,每个视图的全局特征将是该 Voint 的视图特征。
实验 Experiments实验设置 Experimental SetupDatasets 数据集本文对VointNet 进行了基准测试,使用了具有挑战性和现实性的ScanObjectNN数据集。该数据集包含三个变体,包括背景和遮挡,共有15个类别和2,902个点云。
对于形状检索任务,我们使用ShapeNet Core55作为ShapeNet的子集进行基准测试。该数据集包含51,162个带有55个对象类别标签的3D网格对象。根据MVTN的设置从每个网格对象中采样5,000个点来生成点云。
另外,对于形状部件分割任务,在ShapeNet Parts上进行了测试,它是ShapeNet的一个子集,包含来自16个类别和50个部分的16,872个点云对象。
对于遮挡鲁棒性测试,遵循MVTN的方法,在ModelNet40数据集上进行测试,该数据集由40个类别和12,311个3D对象组成。
Metrics 评估指标评估指标方面:
对于3D点云分类任务,展示了整体精度。
对于形状检索任务,使用测试查询的平均精度(mAP)进行评估。
对于语义分割任务,使用点云上的平均交并比(mIoU)进行评估。
对于部件分割任务,展示了实例平均mIoU(Ins. mIoU)。
作为基线方法,包括 PointNet、PointNet++和DGCNN 作为使用点云的基线。
还与一些基于多视图的方法进行了比较,包括 MVCNN、SimpleView和MVTN,用于分类和检索任务,并使用了一些基于多视图的分割方法(如标签融合和Mean Fusion)用于部件分割任务。
VointNet 变量等式 (3) 中的 VointNet 依赖于 VointConv 操作 作为基本构建块。
在这里,简要描述了 VointNet 使用的三个 操作示例。
共享多层感知器 (MLP)这是最基本的 VointConv公式。
对于层 ,视图 处的 Voint 的特征被更新到层 为:,其中 ρ 是共享 MLP,其权重为 ,然后是归一化和非线性函数(例如 ReLU)。
此操作独立应用于所有 Voint,并且仅涉及每个Voint 的可见视图特征。该公式扩展了 PointNet 的共享MLP 公式,以处理 Voints 的视图特征。
图卷积(GCN)通过创建一个连接到所有视图特征的虚拟中心节点来聚合它们的信息(类似于 ViT 中的 “cls” token 来为每个 Voint 定义一个全连接的图。
然后,图卷积可以被定义为共享 MLP(如上所述)但在所有视图特征之间的边缘特征上,然后是图形邻居上的最大池化。在最终输出之前使用额外的共享 MLP。
图注意力(GAT)图注意力操作可以像上面的 GCN 操作一样定义,但是在对它们进行平均之前,在图邻居的特征上学习注意力权重。共享 MLP 计算这些权重。
Implementation Details 实现细节Rendering and Unprojection. 渲染和非投影在pipeline 中选择来自 Pytorch3D的可微点云渲染器 R,因为它的速度和与Pytorch 库的兼容性。在尺寸为 的多视图图像上渲染点云。
根据点的法线值对点进行着色,如果法线不可用,则将它们保持为白色。按照与 (Wei et al, 2020;Hamdi et al, 2021) 类似的程序,视点设置在训练期间随机化(使用 个视图)并在测试中固定为球面视图(使用 个视图)。
Architectures 架构对于二维主干 C,使用 ViT-B(具有来自 TIMM 库的预训练权重)进行分类,使用 DeepLabV3进行分割。
在 3D 点云输出上使用 3D CE 损失以及在像素上定义损失时的 2D CE 损失。VointNet 架构的特征维度为 d = 64,深度在 中为 = 4 层。
主要结果基于VointNet (MLP),除非在第 6 节中另有说明,在第6 节中详细研究了 VointConv 和 C 的影响。
Training Setup 训练设置分两个阶段训练,首先在点的2D 投影标签上训练 2D 主干,然后端到端地训练整个pipeline,同时将训练重点放在 VointNet 部分。
使用 AdamW 优化器 ,初始学习率为 ,步长学习率为每 12 个epoch 33.3%,持续 40 个epoch 。
使用一个 NVIDIATesla V100 GPU 进行训练。不使用任何数据扩充。
有关训练设置(损失和渲染)、VointNet 和 2D 骨干架构的更多详细信息,请参见附录。

表3:3D 形状检索。
- 报告了 ShapeNet Core55 上的 3D 形状检索 mAP。
- VointNet 在此基准测试中取得了最先进的结果。
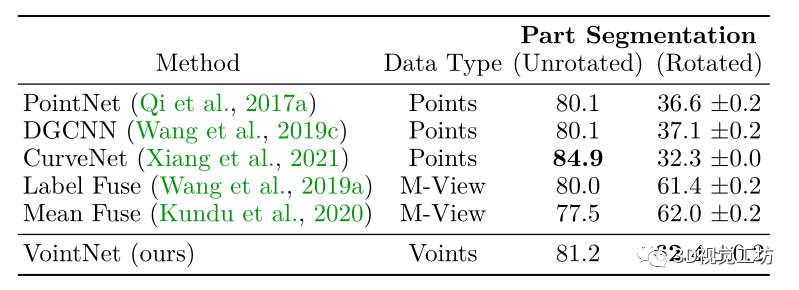
Results 结果表 4:ShapeNetPart 上的稳健 3D 部件分割。
在 ShapeNetPart 的 3D 分割中,VointNet 的 mIoU 与其他方法的对比。
Voint 的主要测试结果总结在表 2、3、4 和 5 中。在 3D 分类、检索和稳健的 3D 零件分割任务中实现了最先进的性能。
表 2 报告了 ScanObjectNN 上 3D点云分类任务的分类精度。它将 VointNet 与其他最近的强大基线进行基准测试 。

图 3:部件分割的定性比较。
- 将 VointNet 3D 分割预测与使用相同训练的 2D 主干的 Mean Fuse进行比较。
- 请注意 VointNet 如何区分细节部分(例如车窗框)。
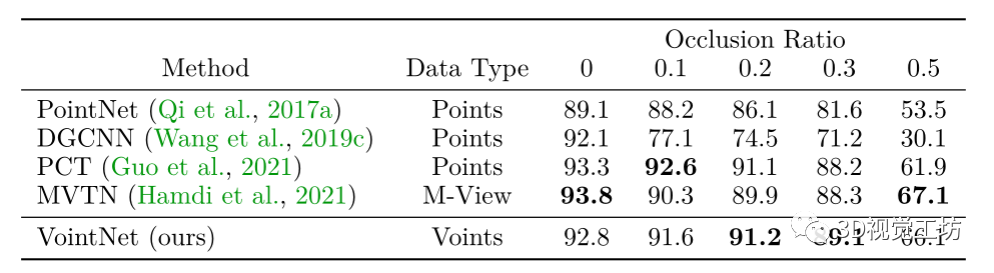
3D 形状检索表 5:3D 分类的遮挡稳健性。
报告了 ModelNet40上针对不同数据遮挡率的测试准确性,以衡量不同 3D 方法的遮挡稳健性。
表 3 在 ShapeNet Core55上对 3D 形状检索 mAP 进行了基准测试。
VointNet 在 ShapeNet Core55 上实现了最先进的性能。报告了基线结果。
稳健的 3D 部件分割表 4 报告了 VointNet 的实例平均分割 mIoU 与ShapeNet Parts 上的其他方法相比。报告了基准测试的两个变体:未旋转的归一化设置和旋转的真实设置。
图 3 显示了 VointNet 和 Mean Fuse 的定性 3D 分割结果与ground truth相比。
Occlusion Robustness 遮挡稳健性最近研究的 3D 分类模型的稳健性方面之一是它们对遮挡的稳健性,如 MVTN 所述。这些模拟遮挡在测试时引入,并报告每个裁剪率的平均测试精度。
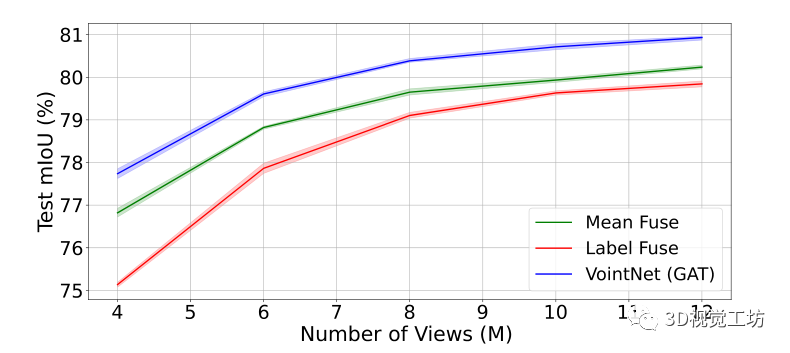
图 4:视图数量的影响。绘制 Ins。
- 3D 分割的mIoU 与 ShapeNet 部件推理中使用的视图数 (M)。
- 请注意 VointNet 对 Mean Fuse 和 Label Fuse的持续改进。
- 两个基线都使用与 VointNet 相同的经过训练的 2D 主干,并在相同的未旋转设置上进行测试。

Analysis and Insights 分析和见解Number of Views 视图数量表 6:3D 分割的消融研究。
- 消融了 VointNet 的不同组件(2D 主干和VointConv 选择)并报告 Ins。
- mIoU 在 ShapeNetPart上的表现。
研究了视图数量 M 对使用多个视图的 3D 部件分割性能的影响。将 Mean Fuse 和 Label Fuse 与我们的VointNet 进行比较,因为它们都具有相同的训练的2D 主干。
消融了 2D 主干的选择和 VointNet 中使用的VointConv 操作,并报告了分割 Ins。表 6 中的 mIoU结果。
在附录中提供了更多因素以及计算和内存成本的详细研究。
Limitations and Acknowledgments 局限性和未来工作这项工作介绍了 Voint cloud表示,它继承了点云的优点和多视图投影的丰富视觉特征,导致增强的多视图聚合和在许多 3D 视觉任务上的强大性能。
解决这些局限性是未来工作的重要方向。此外,将Voint 学习扩展到更多 3D 任务(如 3D 场景分割和 3D对象检测)留给未来的工作。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

