数据增强改进
数据增强不仅关乎模型的精度,也对训练的效率有着巨大的影响。随着 GPU 计算性能的不断增加,模型前向和反向传播的速度在不断提升。
然而,当我们在训练工业级的模型时,由于引入大量的数据增强,CPU 的计算能力以及存储的 IO 往往成为了制约模型训练速度的瓶颈。尤其是当使用了 YOLO 系列中广泛使用的 Mosaic 和 MixUp 这样涉及到多张图片混合的数据增强,由于需要读取和处理的图片数量成倍增加,数据增强的耗时也大幅增加。 图 6. Mosaic MixUp 数据增强效果图为了解决多图混合数据增强的耗时问题,我们在这些数据增强中引入了缓存机制。我们使用一个缓存队列将历史的图片保存下来,当需要进行图片混合操作时,不再通过 dataset 重新加载图片,而是从缓存队列中随机选取历史的图片进行混合。
图 6. Mosaic MixUp 数据增强效果图为了解决多图混合数据增强的耗时问题,我们在这些数据增强中引入了缓存机制。我们使用一个缓存队列将历史的图片保存下来,当需要进行图片混合操作时,不再通过 dataset 重新加载图片,而是从缓存队列中随机选取历史的图片进行混合。
通过实验发现,当缓存队列足够大,且使用随机出队的方式时,训练得到的模型精度与传统的 Mosaic & MixUp 并无区别。由于引入了缓存机制,两种数据增强的运行效率得到了大幅提升。
通过使用 MMDetection 中的 benchmark 工具 tools/analysis_tools/benchmark.py,我们将 RTMDet 与以高效训练著称的 YOLOv5 的数据增强进行了对比:
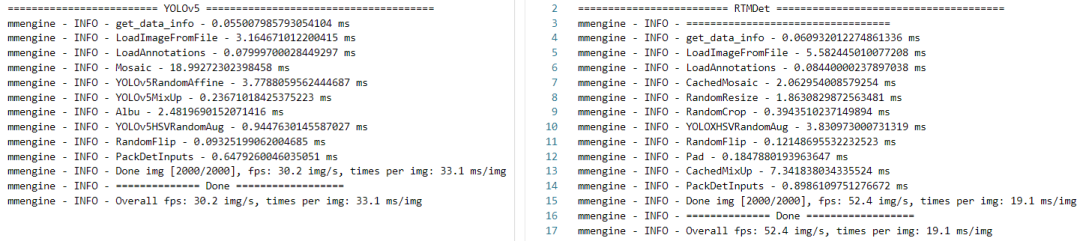
YOLOv5 的数据增强(MixUp 概率仅为 0.1)的吞吐量:Overall fps: 30.2 img/s, times per img: 33.1 ms/img;RTMDet 的数据增强(MixUp 全程开启)的吞吐量:Overall fps: 52.4 img/s, times per img: 19.1 ms/img。
从 benchmark 的结果来看, RTMDet 在全程开启图像混合的数据增强的情况下,数据处理吞吐量依然显著高于 YOLOv5,每秒处理的图片数量达到了 YOLOv5 的 1.7 倍!使用缓存机制加速的 Mosaic 和 MixUp 已经在 MMYOLO 中得到了全面的支持,不仅 RTMDet 可以使用,YOLOv5,v6,v7上都可以通过 use_cached=True 开关直接开启,真正做到了一键加速训练!除了优化数据增强的运行效率,我们也对数据增强的逻辑进行了优化。我们分析了 YOLOX 的数据增强后发现了其中的问题:YOLOX 使用强弱两个阶段的数据增强,但其第一个训练阶段引入了旋转和切变等操作,导致标注框产生了比较大的误差,使其第二个训练阶段需要对回归分支额外增加一个 L1 loss 来对回归任务进行修正。这就造成了数据增强与模型的损失函数设计产生了耦合。为了使数据增强和模型解耦,得到更通用的增强策略,我们选择在第一个训练阶段不引入导致标注误差的数据增强,而是通过增加 Mosaic MixUp 混合图片的数量来提升强度,我们将总体混合的图片数量从 YOLOX 使用的 5 张增加至 8 张。得益于上文提到的缓存机制,增加混合图片的数量并不会导致训练速度变慢。在第二个训练阶段,我们关闭 Mosaic 和 MixUp,转而使用 Large Scale Jitter(LSJ),使模型在更符合原数据集特征分布的状态下微调。通过对比实验可以看出,我们的数据增强显著优于之前的方法: 表 7. 数据增强训练精度对比
表 7. 数据增强训练精度对比最终效果
通过上文的种种改进,我们最终得到了 RTMDet 系列模型,我们可以将实验拆解,并逐个应用在我们的对照组模型 YOLOX 之上,来解析如何从 YOLOX 一步一步修改为 RTMDet: 表 8. 从 YOLOX 到 RTMDet step-by-step 对比首先,为了解决 CosineLr 学习率衰减过快以及 SGD 收敛不稳定的问题,我们将优化器以及学习率分别更换为了 AdamW 和 FlatCosineLR,得到了 0.4% 的提升。然后我们使用新的基础单元构建而成的 backbone 和 neck 替换了原有的模型结构,这一改进又提升了 1.2% 的 AP,并且推理速度只减慢了 0.02ms。在使用共享权重的检测头后,参数量过大的问题得到了解决,而模型精度和推理速度都没有下降。在此基础之上,我们又增加了动态软标签分配策略以及改进后的数据增强,分别带来了 1.1% 和 1.3% 的精度提升。最后,锦上添花的一点,我们又将 backbone 在 imagenet 上进行了预训练,也使精度得到了略微的提升。不过预训练模型仅在 tiny 和 s 模型上有精度提升的效果,在更大的模型结构上则体现不出优势。综合以上这些修改,RTMDet 相比于 YOLOX 在相似的模型大小以及推理速度上提升了 4.3% AP!通过调整深度以及宽度的系数进行模型缩放,我们最终得到了 tiny/s/m/l/x 五种不同大小的模型,在不同量级上均超越了同级别的模型:
表 8. 从 YOLOX 到 RTMDet step-by-step 对比首先,为了解决 CosineLr 学习率衰减过快以及 SGD 收敛不稳定的问题,我们将优化器以及学习率分别更换为了 AdamW 和 FlatCosineLR,得到了 0.4% 的提升。然后我们使用新的基础单元构建而成的 backbone 和 neck 替换了原有的模型结构,这一改进又提升了 1.2% 的 AP,并且推理速度只减慢了 0.02ms。在使用共享权重的检测头后,参数量过大的问题得到了解决,而模型精度和推理速度都没有下降。在此基础之上,我们又增加了动态软标签分配策略以及改进后的数据增强,分别带来了 1.1% 和 1.3% 的精度提升。最后,锦上添花的一点,我们又将 backbone 在 imagenet 上进行了预训练,也使精度得到了略微的提升。不过预训练模型仅在 tiny 和 s 模型上有精度提升的效果,在更大的模型结构上则体现不出优势。综合以上这些修改,RTMDet 相比于 YOLOX 在相似的模型大小以及推理速度上提升了 4.3% AP!通过调整深度以及宽度的系数进行模型缩放,我们最终得到了 tiny/s/m/l/x 五种不同大小的模型,在不同量级上均超越了同级别的模型: 表 9. RTMDet 与其他同级别模型的性能对比(推理测速使用 3090 GPU,TensorRT 8.4.3)另外,我们还在工业界常用的 T4 GPU 上进行了测速,效果如下表所示:
表 9. RTMDet 与其他同级别模型的性能对比(推理测速使用 3090 GPU,TensorRT 8.4.3)另外,我们还在工业界常用的 T4 GPU 上进行了测速,效果如下表所示:| Model | latency(ms) | FPS |
| RTMDet-tiny | 2.34 | 427.35 |
| RTMDet-s | 2.96 | 337.84 |
| RTMDet-m | 6.41 | 156.01 |
| RTMDet-l | 10.32 | 96.90 |
| RTMDet-x | 18.80 | 53.19 |
表 10. RTMDet 在 T4 GPU 上的推理速度(测速使用 TensorRT 8.4,FP16,batchsize=1)多项任务取得 SOTA
为了验证 RTMDet 算法的通用性,我们通过仅增加任务头的方式,对模型进行了最小限度的修改,将其拓展至了实例分割以及旋转目标检测任务上。在仅进行了非常简单的修改的情况下,RTMDet 也依然取得了 SOTA 的效果! 图 7. RTMDet 在三种不同任务上的可视化效果
图 7. RTMDet 在三种不同任务上的可视化效果实例分割
传统的实例分割往往采用双阶段的方式来预测 mask,但近两年来,基于 kernel 的方法正逐渐兴起。为了保持单阶段检测器的简洁高效和易于部署的特性,我们参考 CondInst 为 RTMDet 增加了 mask head 以及 kernel head。mask head 由 4 个卷积层组成,通过 neck 输出的多尺度特征预测出维度为 8 的 mask prototype feature。而 kernel head 则为每个 instance 预测 169 维的向量,从而组成 3 个动态卷积的卷积核,与 mask feature 进行交互,最终得到每个 instance 的 mask。 图 8. RTMDet-Ins 实例分割分支示意图为了最大化利用 mask 的标注信息,我们还将标签分配中的中心先验代价的检测框中心修改为了 mask 的重心。为了与其他实例分割方法做公平对比,我们使用 ResNet50 FPN 12 epoch 的标准 setting 进行了实验,同时参考 CondInst 加入了语义分割的辅助分支加快收敛。实验结果表明,我们的方法在标准 setting 下,不仅超越了 CondInst,SOLOv2 等单阶段模型,也超越了 Cascade Mask R-CNN 这样的多阶段模型。在使用与 RTMDet 一致的模型结构以及训练策略后,得到的 RTMDet-Ins 模型,精度不仅大幅超越 YOLOv5-seg,也超越了前几天刚刚推出的 YOLOv8,取得了实时实例分割的 SOTA。
图 8. RTMDet-Ins 实例分割分支示意图为了最大化利用 mask 的标注信息,我们还将标签分配中的中心先验代价的检测框中心修改为了 mask 的重心。为了与其他实例分割方法做公平对比,我们使用 ResNet50 FPN 12 epoch 的标准 setting 进行了实验,同时参考 CondInst 加入了语义分割的辅助分支加快收敛。实验结果表明,我们的方法在标准 setting 下,不仅超越了 CondInst,SOLOv2 等单阶段模型,也超越了 Cascade Mask R-CNN 这样的多阶段模型。在使用与 RTMDet 一致的模型结构以及训练策略后,得到的 RTMDet-Ins 模型,精度不仅大幅超越 YOLOv5-seg,也超越了前几天刚刚推出的 YOLOv8,取得了实时实例分割的 SOTA。 表 11. RTMDet-Ins 与其他实例分割算法的性能对比
表 11. RTMDet-Ins 与其他实例分割算法的性能对比旋转目标检测
旋转目标检测是遥感领域使用最广泛的方法,而将 RTMDet 拓展至此任务也非常简单,得益于 MMDetection 3.0 版本,我们只需要增加回归分支的输出特征维度,增加角度分量,同时更换 box 的编****,便能让 RTMDet 支持预测旋转框。由于旋转框与普通目标检测任务仅有回归分支有差异,因此旋转框的模型也能够加载目标检测的预训练模型并从中受益。我们在遥感领域最常用的 DOTA 数据集上验证了我们的方法,结果表明,我们的模型不仅超越了众多的多阶段方法,也超越了之前最优的算法 PPYOLOE-R,成为了 SOTA。 图 9. RTMDet-R 与其他旋转目标检测方法在 DOTA 数据集上的对比为了验证模型的泛化能力,我们还在 DOTA 1.5 以及 HRSC 两个数据集上进行了训练,也同样取得了最优的结果。
图 9. RTMDet-R 与其他旋转目标检测方法在 DOTA 数据集上的对比为了验证模型的泛化能力,我们还在 DOTA 1.5 以及 HRSC 两个数据集上进行了训练,也同样取得了最优的结果。 表 12. RTMDet-R 在 DOTA 1.5 上的性能
表 12. RTMDet-R 在 DOTA 1.5 上的性能 表 13. RTMDet-R 在 HRSC 上的性能,仅使用 tiny 模型就超越了之前的多阶段算法
表 13. RTMDet-R 在 HRSC 上的性能,仅使用 tiny 模型就超越了之前的多阶段算法总结
通过在模型结构的基本单元引入大 kernel 深度可分离卷积增大感受野,并平衡不同分辨率层级间以及 backbone 和 neck 间的计算量、参数量平衡,改进标签分配以及数据增强策略,RTMDet 不论是在目标检测任务上,还是在实例分割以及旋转目标检测任务上,均取得了优异的性能。我们希望我们探索出的这些改进方案能够对设计实时的目标检测模型有所启发,也希望我们在工程及算法上的优化能够在实际的工业场景中有所应用。最后,别忘了给 MMDetection、MMYOLO、MMRotate 点个 Star 哦~
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

