来源丨MCPRL
导读
传统语义分割在很多任务上已经达到了很好的性能,然而这需要大规模完全标注的数据集,这无疑需要昂贵的人力物力财力。半监督语义分割旨在利用少量标注样本和大量的未标记样本解决标注难度大、标注成本昂贵等问题。本文将焦距近期半监督语义分割的前沿论文,分析其方法和特点并给出总结。
1 背景
定义:使用大量的未标记数据,以及同时使用标记数据,来进行语义分割。常用数据集:PASCAL VOC 2012;Cityscapes等
常用分割网络:不同backbone的deeplabv3+;HRNet;PSPNet等常用方法:主要包括Pseudo-Labels based和Consistency based,Pseudo-Labels based就是基于伪标签进行监督学习的方法, 一般就是模型对unlabeled data预测伪标签,然后进行监督学习;Consistency based就是利用数据增强、网络扰动等方法,但认为模型的输出应该保持一致,可以看作一种正则化方法以提高模型的泛化性,防止网络对有标签数据的过拟合,让模型提取出最本质的特征。2 论文列表
本文分析的论文如下: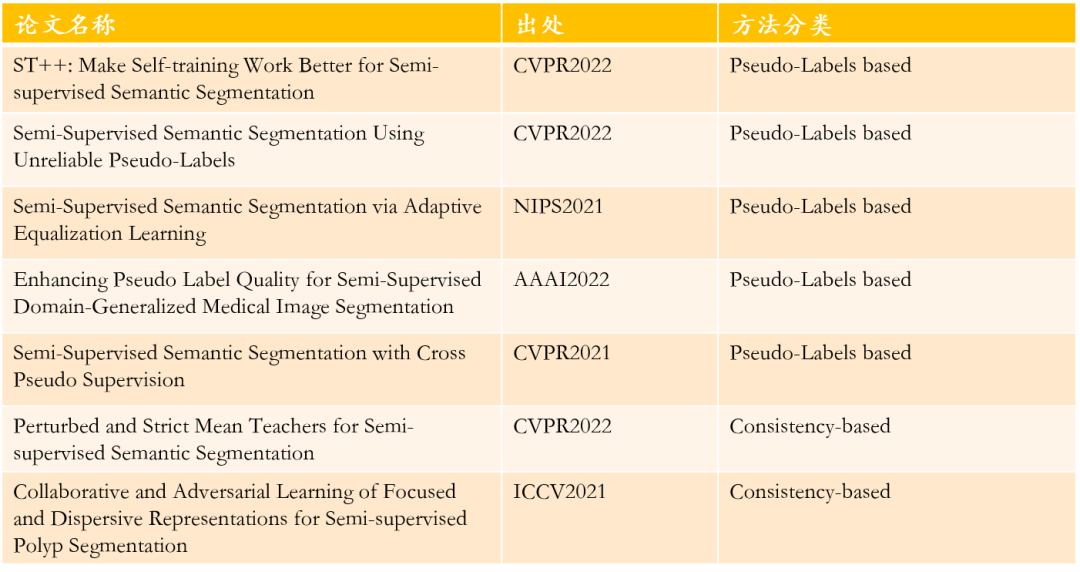
3 ST++: Make Self-training Work Better for Semi-supervised Semantic Segmentation
第一篇就是CVPR2022的ST++,它具有两大出发点:- 对于半监督语义分割来说,一些精细的机制(指加的一些tricks)是必不可少的吗?更重要的是,self-train对于这项任务来说已经过时了吗?针对这个出发点,作者就使用self-train策略,利用常用的数据增强,而没有用其他花哨的tricks,产生ST模型
- 第二个出发点就是,以前的方法,同时利用了所有的unlabeled data,而不同的未标记图像不可能同样简单,对应的伪标签也不可能同样可靠,因此在使用有些不可靠的伪标签迭代优化模型时,会导致严重的预测偏差和潜在的性能下降。因此,作者提出ST++进行重新训练,它会基于伪mask在不同迭代轮次中的整体稳定性自动选择和优先排序更可靠的图像,为剩下的不可靠的图像生成更高质量的人工标签。
基本的self-train范式如下:- 【有监督预训练】在有标签图像上完全训练得到一个初始的教师模型T
- 【生成伪标签】用教师模型在所有的无标签图像上预测one-hot伪标签
- 【重新训练】混合有标签图像和无标签图像及其伪标签,在其上重新训练一个学生模型S,用于最终的测试
而原始的ST存在两个问题:基于Teacher模型的伪标签可能是错的,导致学生模型对噪声标签过拟合问题;T和S的网络结构相同,初始化相似,容易对未标记的图像做出相似的真假预测,导致学生S除了熵最小化外,没有学到额外的信息。为了解决上述两个问题,我们改进的ST为S模型引入了强数据增强(colorjitter, grayscale, blur, Cutout),来防止这种过拟合。 其实就是用T产生的伪标签和真的标签一起进行监督学习训练S,而且对S的unlabelled data加了强数据增强。ST++就是再ST的基础上通过观察T在训练过程中产生伪标签的图像稳定性,来对可靠的未标记样本进行优先级排序和选择,防止不可靠样本损害网络训练。具体地,作者观察到在训练阶段,分割性能和所生产的伪掩码的进化稳定性之间存在正相关。因此,在训练过程中,可以根据进化稳定性选择更可靠、预测效果更好的未标记图像。所以将前K-1个checkpoint的mask与第K个求一个meanIOU,认为值越高,可靠性越强。完整的ST++见下图:
其实就是用T产生的伪标签和真的标签一起进行监督学习训练S,而且对S的unlabelled data加了强数据增强。ST++就是再ST的基础上通过观察T在训练过程中产生伪标签的图像稳定性,来对可靠的未标记样本进行优先级排序和选择,防止不可靠样本损害网络训练。具体地,作者观察到在训练阶段,分割性能和所生产的伪掩码的进化稳定性之间存在正相关。因此,在训练过程中,可以根据进化稳定性选择更可靠、预测效果更好的未标记图像。所以将前K-1个checkpoint的mask与第K个求一个meanIOU,认为值越高,可靠性越强。完整的ST++见下图: 具体步骤:
具体步骤:- 在labeled data上训练T,并根据meanIOU筛选可靠的unlabeled data
- 用labeled data和可靠的unlabeled data第一次训练S
- 训练好的模型对不可靠的unlabeled data重新预测生成伪标签
- 用所有数据对S进行第二次训练
- 整个训练过程还可以继续迭代,利用自身模型性能的提升和数据不断清洗形成正反馈。
4 Semi-Supervised Semantic Segmentation With Cross Pseudo Supervision
这一篇CPS来自于CVPR2021,,其思想非常简单,就是利用网络扰动,即两个具有相同架构的不同初始化的网络进行交叉监督,来达到提升模型预测稳定性的作用。它结合Cutmix数据增强和CELoss就可达到当时SOTA。 具体地,相同的数据塞入两个架构相同、不同初始化的网络,通过sofmax产生预测P,然后再生成最终的伪标签Y,这里用Y1监督P2,反之亦然,使用了一个交叉监督的思想,可以同时达到利用伪标签监督(且增加了监督信号)和一致性约束的效果。
具体地,相同的数据塞入两个架构相同、不同初始化的网络,通过sofmax产生预测P,然后再生成最终的伪标签Y,这里用Y1监督P2,反之亦然,使用了一个交叉监督的思想,可以同时达到利用伪标签监督(且增加了监督信号)和一致性约束的效果。5 Perturbed and Strict Mean Teachers for Semi-supervised Semantic Segmentation
这篇文章也是出自CVPR2022,是一个利用一致性损失的经典方法。它主要贡献就是:1. 通过一个新的辅助教师和一个更严格的信心加权的CE损失(Conf-CE)来替代MT的MSE损失,提高了未标记训练图像的分割精度,和更好的收敛——架构、损失函数层面2. 结合使用输入数据、特征和网络扰动,以改进模型的泛化3. 提出一种新型的特征扰动,称为T-VAT,基于从我们的MT模型的教师那里学习到的对抗性噪声,并将其应用于学生模型,从而产生具有挑战性的噪声,以促进学生模型的有效训练。——扰动层面 具体的细节就是:增加了一个T模型,对两个T模型只使用弱数据增强(比如flip、crop、scale),防止对T模型的预测造成干扰;对S模型进行强数据增强(Cutmix,Zoom in/ Out)然后,对S编码后的特征层使用T-VAT扰动,增加模型泛化性,使编码器能提取最本质的特征。这个扰动要足够大足够有效,如何衡量?就是用两个T模型的预测来衡量,要让T模型的预测在加噪声前后,预测的差异越大越好。然后就是两个T模型的预测和S的预测使用Conf-CE Loss作为一致性损失函数:
具体的细节就是:增加了一个T模型,对两个T模型只使用弱数据增强(比如flip、crop、scale),防止对T模型的预测造成干扰;对S模型进行强数据增强(Cutmix,Zoom in/ Out)然后,对S编码后的特征层使用T-VAT扰动,增加模型泛化性,使编码器能提取最本质的特征。这个扰动要足够大足够有效,如何衡量?就是用两个T模型的预测来衡量,要让T模型的预测在加噪声前后,预测的差异越大越好。然后就是两个T模型的预测和S的预测使用Conf-CE Loss作为一致性损失函数: 就是在CELoss加了一个权重c(w)代表w像素位置的分割置信度,置信度越高,损失越大,这样对于不那么可靠的像素,损失较小,可一定程度上缓解对于错误标签的过拟合,而对于Labeled data就用监督损失函数CELoss然后梯度下降更新S,EMA交替更新T,即一个epoch只更新一个T模型。可以看到这个文章改进思路比较全面,输入数据、特征和网络三个层面的扰动和架构损失函数的改进都考虑到了。
就是在CELoss加了一个权重c(w)代表w像素位置的分割置信度,置信度越高,损失越大,这样对于不那么可靠的像素,损失较小,可一定程度上缓解对于错误标签的过拟合,而对于Labeled data就用监督损失函数CELoss然后梯度下降更新S,EMA交替更新T,即一个epoch只更新一个T模型。可以看到这个文章改进思路比较全面,输入数据、特征和网络三个层面的扰动和架构损失函数的改进都考虑到了。6 Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
 这篇文章出发点就是现有Pseudo-Labels based方法大多扔掉置信度不高的伪标签,只使用置信度高的伪标签进行训练;然而,这会导致有些像素可能永远不会被训练。从而导致某些类别训练不充分或者类不平衡。解决方案:虽然有些不靠谱的伪标签可能是misclassified,但是我可以排除一些绝不可能的类别。利用什么来拉远这些类别的距离?对比学习损失InfoNCELoss
这篇文章出发点就是现有Pseudo-Labels based方法大多扔掉置信度不高的伪标签,只使用置信度高的伪标签进行训练;然而,这会导致有些像素可能永远不会被训练。从而导致某些类别训练不充分或者类不平衡。解决方案:虽然有些不靠谱的伪标签可能是misclassified,但是我可以排除一些绝不可能的类别。利用什么来拉远这些类别的距离?对比学习损失InfoNCELoss 所以它的基本思路是:对于labeled data正常监督学习,对于unlabeled样本首先根据阈值划分出可靠像素和不可靠的像素,可靠像素使用监督学习,不可靠的像素使用对比学习拉远与不可能类别之间的距离。
所以它的基本思路是:对于labeled data正常监督学习,对于unlabeled样本首先根据阈值划分出可靠像素和不可靠的像素,可靠像素使用监督学习,不可靠的像素使用对比学习拉远与不可能类别之间的距离。7 Semi-Supervised Semantic Segmentation via Adaptive Equalization Learning
这是NIPS2021的一篇,着重于解决长尾、类不平衡问题,比如说Cityscapes数据集,头部类别的像素数远多于尾部类别几百倍。为了应对数据集中的这种问题,本文提出了三大自适应策略:1)自适应复制-粘贴和CutMix数据增强方法,为表现不佳的类别提供更多被复制或剪切的机会2)自适应数据采样方法,鼓励从表现不佳的类别中采样像素3)一种简单而有效的重加权方法,以缓解伪标记带来的训练噪声 通过这些策略,我们可以一定程度上缓解长尾问题,比如Cityscape数据集的两种设置,我们从图中看到,从蓝线变成了黄线,很大程度上缓解了长尾问题基本网络框架如下:
通过这些策略,我们可以一定程度上缓解长尾问题,比如Cityscape数据集的两种设置,我们从图中看到,从蓝线变成了黄线,很大程度上缓解了长尾问题基本网络框架如下: 基本策略和经典方法一样,经典的mean Teacher模型,采用EMA的方法更新T,采用梯度回传更新S利用T模型在弱增广无标记数据Du上生成一组伪标签, 随后,用gt对标记数据Dl(弱增强)和用生成的伪标签对未标记数据Du(强增强)进行训练。损失函数也是标准的利用伪标签的方法,使用了CELoss
基本策略和经典方法一样,经典的mean Teacher模型,采用EMA的方法更新T,采用梯度回传更新S利用T模型在弱增广无标记数据Du上生成一组伪标签, 随后,用gt对标记数据Dl(弱增强)和用生成的伪标签对未标记数据Du(强增强)进行训练。损失函数也是标准的利用伪标签的方法,使用了CELoss 其使用的自适应策略如下:首先构建Confidence Bank:计算一个batch中的c类像素的平均预测概率,然后随着训练的进行,这一个值采用EMA更新。
其使用的自适应策略如下:首先构建Confidence Bank:计算一个batch中的c类像素的平均预测概率,然后随着训练的进行,这一个值采用EMA更新。
 然后使用Adaptive CutMix数据增强:置信度越高的类别选择进行Cutmix的概率越低,对所有类别使用Softmax得到选取的概率。具体地,作者依据概率随机选取一个类别,作为采样类别,随机选取一幅包含采样类别的未标记图像,然后对该类别区域Crop,再粘到另一幅图像上;由于自适应CutMix是在没有标注的数据上执行的,因此我们使用T的预测作为近似gt。
然后使用Adaptive CutMix数据增强:置信度越高的类别选择进行Cutmix的概率越低,对所有类别使用Softmax得到选取的概率。具体地,作者依据概率随机选取一个类别,作为采样类别,随机选取一幅包含采样类别的未标记图像,然后对该类别区域Crop,再粘到另一幅图像上;由于自适应CutMix是在没有标注的数据上执行的,因此我们使用T的预测作为近似gt。 然后进行Adaptive Copy-Paste:思路同CutMix,只不过将采样类别的所有像素随机粘到另一张图像上。然后使用Adaptive Equalization Sampling:就是在训练集每个图象中的每一个类别按一定采样率采样,采样到的像素计算损失。
然后进行Adaptive Copy-Paste:思路同CutMix,只不过将采样类别的所有像素随机粘到另一张图像上。然后使用Adaptive Equalization Sampling:就是在训练集每个图象中的每一个类别按一定采样率采样,采样到的像素计算损失。 越困难的类别采样率越高,可以看到置信率最低的样本采样率为1;只对被采样到的像素计算损失
越困难的类别采样率越高,可以看到置信率最低的样本采样率为1;只对被采样到的像素计算损失 作者还采用了Dynamic Re-Weighting:按照分为c类的置信度进行加权,置信度越高,损失越大
作者还采用了Dynamic Re-Weighting:按照分为c类的置信度进行加权,置信度越高,损失越大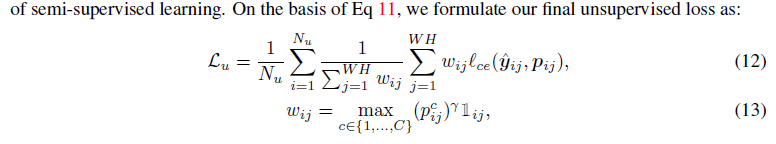
8 Enhancing Pseudo Label Quality for Semi-Supervised Domain-Generalized Medical Image Segmentation
这一篇是用在医学图像CT上的半监督域扩展语义分割,解决Domain-Generalize问题:训练数据由来自三个源域的标记图像和未标记图像组成,且不知道域标签,而测试数据来自一个未知分布。方法主要是借鉴CPS交叉监督提出 confidence-aware cross pseudo supervision,并且使用了使用傅里叶特征做数据增强。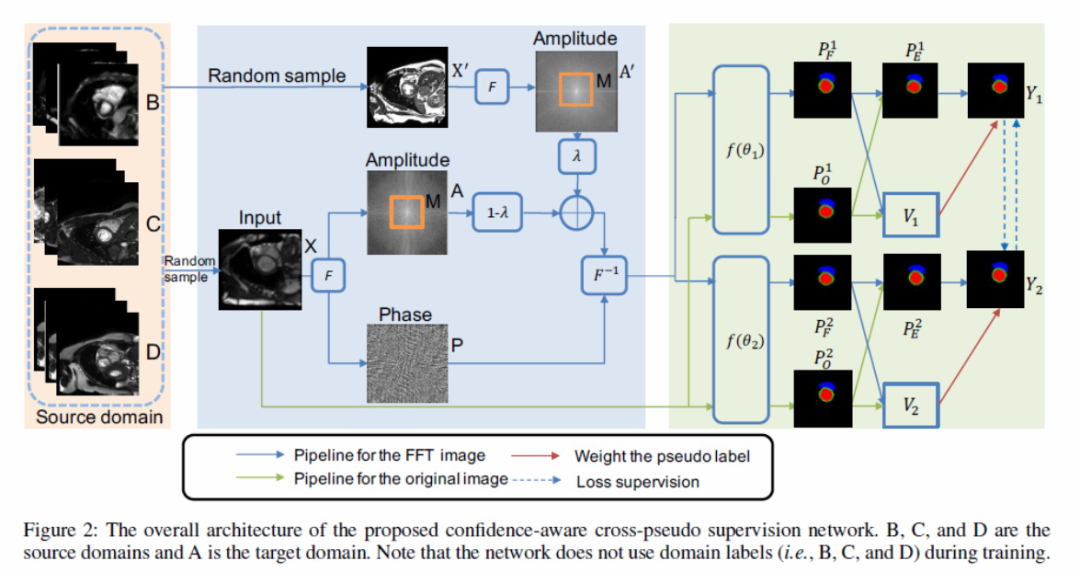
9 Collaborative and Adversarial Learning of Focused and Dispersive Representations for Semi-supervised Polyp Segmentation
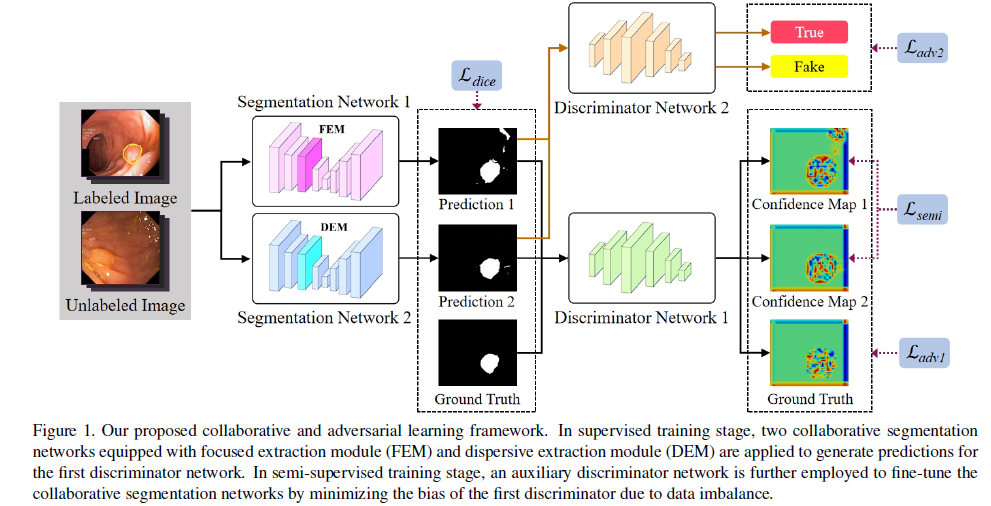
- 这篇是半监督方法用在息肉分割上的,主要提出了两个提取模块,在两个分割网络的编码路径上分别采用FEM和DEM。FEM使我们的网络能够捕捉到输入特征图的重点信息,如位置信息和空间信息,而DEM试图聚合输入的零散边界信息。
- 同时训练两个分割网络和一个discriminator网络标记图像通过对抗训练方法。在一致性约束的帮助下,我们可以利用FEM和DEM的两种特征映射,通过训练好的鉴别器网络生成具有高可信度的置信度映射;
- 提出了另一种对抗训练方法——辅助对抗学习(AAL),以提高半监督训练阶段未标记图像分割预测的质量。我们采用一种新的鉴别器对有标记图像的分割结果分配真标签,对无标记图像的预测分配假标签。使用AAL可以得到可信度较高的置信图,从而更好地应用于分割网络
10 总结
- 半监督语义分割目前的改进方向主要包括:图像、特征、网络层级的扰动;网络架构(目前较少);损失函数(更细的改动,结合consistency-based 和 pseudo-based);训练策略(更细致的策略)
- 可融合的方向:对比学习、相似度学习可作为突破口,可能可以结合弱监督、无监督方法。
撰稿人、排版人:董军豪
本文仅做学术分享,如有侵权,请联系删文。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

