简介多视图投影方法在 3D 分类和分割等 3D 理解任务上表现出了良好的性能。然而,目前尚不清楚如何将这种多视图方法与广泛使用的 3D 点云相结合。
人类视觉系统更接近于使用多个视角的间接方法来理解3D物体,而不是直接处理3D数据。相比之下,间接方法通常通过渲染对象或场景的多个2D视图,并使用基于2D图像的传统架构来处理每个图像。人类视觉系统更接近于这种多视图间接方法,因为它接收到的是渲染图像流,而不是显式的3D数据。
引入了Voint cloud这个新的3D数据表示形式,并设计了VointNet 模型来学习和处理这种表示。Voint cloud将每个3D点表示为从多个视角提取的特征集合,以融合点云表示的紧凑性和多视图表示的自然感知能力。
作者通过定义在Voint级别的池化和卷积操作,构建了Voint neural network (VointNet ),并利用该网络在Voint空间学习3D表示。
多视图投影方法在 3D 分类和分割等 3D 理解任务上表现出了良好的性能。然而,目前尚不清楚如何将这种多视图方法与广泛使用的 3D 点云相结合。以前的方法使用未学习的启发式方法在点级别组合特征。
为此,本文引入了多视点云(Voint cloud)的概念,将每个 3D 点表示为从多个视点提取的一组特征。这种新颖的 3D Voint 云表示结合了 3D 点云表示的紧凑性和多视图表示的自然视图感知。自然地,可以为这个新的表示配备卷积和池化操作。
通过部署一个 Voint 神经网络 (VointNet ) 来学习Voint 空间中的表征。学习的新颖表示在标准基准(ScanObjectNN、ShapeNet Core55 和 ShapeNetParts)的 3D 分类、形状检索和稳健的 3D 部件分割方面均实现了最先进的性能。
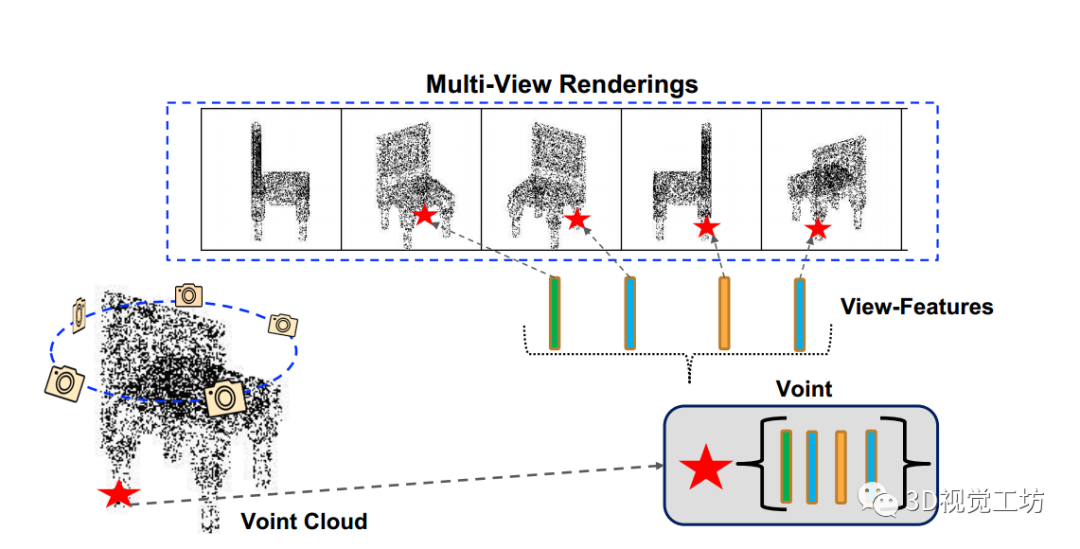
笔者个人体会图1: 3D Voint clouds。本文提出了多视图点云(Voint cloud),这是一种新颖的3D表示,它紧凑且自然地描述了3D点云的视图投影。
- 3D云中的每个点都被标记为一个点,它会累积该点的视图特征。
- 注意,并非所有的3D点在所有视图中都可见。Voint 的集合构成了一个Voint cloud。
作者的动机是解决在3D视觉任务中如何表示3D数据的问题。
作者观察到在2D计算机视觉中,直接采用图像作为输入的方法取得了巨大的成功,而在3D视觉中,如何表示和处理3D数据仍然是一个挑战。
尽管深度学习在2D计算机视觉中取得了巨大成功,但在3D视觉中,如何表示和处理3D数据仍然是一个挑战。
3D计算机视觉和计算机图形学的一个基本问题是如何表示3D数据。深度学习在2D计算机视觉领域的成功,它在3D视觉和图形领域的广泛应用变得尤为重要。深度网络已经在多个3D任务上取得了成功,包括3D分类、3D分割、3D检测、3D重建和新颖视图合成。这些方法可以依赖于直接的3D表示、图像上的间接2D投影,或者两者的混合。直接方法操作通常以点云、网格或体素的形式表示的3D数据。
作者认为间接的多视图方法更符合人类视觉系统的工作方式,因为人类接收到的是一系列渲染图像,而不是显式的3D数据。
人类视觉系统更接近于使用多个视角的间接方法来理解3D物体,而不是直接处理3D数据。
相比之下,间接方法通常通过渲染对象或场景的多个2D视图,并使用基于2D图像的传统架构来处理每个图像。人类视觉系统更接近于这种多视图间接方法,因为它接收到的是渲染图像流,而不是显式的3D数据。
多视图方法在3D形状分类和分割任务中已经取得了令人印象深刻的性能。然而,在多视图表示中,如何正确聚合每个视图的特征是一个挑战。
使用间接方法处理3D视觉任务具有三个主要优势:(i) 成熟且可迁移的2D计算机视觉模型(如CNN、Transformers等),(ii) 大型和多样化标记图像数据集的预训练支持(例如ImageNet),(iii) 多视图图像提供了丰富的上下文特征,根据视角提供信息,与几何3D邻域特征不同。
多视图方法在3D形状分类和分割方面取得了令人印象深刻的性能。然而,多视图表示(特别是在密集预测任务中)的挑战在于如何正确地聚合每个视图的特征以获得具有代表性的3D点云。需要进行适当的聚合操作,以获得每个点具有适用于典型点云处理流程的单个特征。
因此,动机是将多视图的思想与常用的3D点云表示相结合,以提高3D理解任务的性能。
以前的多视图方法依赖于启发式方法,例如将像素映射到点后进行平均或池化,或者与体素进行多视图融合。然而,这种启发式方法存在一些问题:(i) 这种方法可能会汇总来自不同视角的误导性预测信息。例如,如果一个对象从底部视角独立处理,而与其他视角结合时会产生错误的信息。(ii) 视图缺乏几何3D信息。
为了解决这些问题,提出了一种新的混合3D数据结构,它继承了点云的优点(紧凑性、灵活性和3D描述性),并利用了多视图投影丰富的感知特征。这种新的表示称为多视图点云(或Voint cloud)。
引入了Voint cloud这个新的3D数据表示形式,并设计了VointNet 模型来学习和处理这种表示。
Voint cloud将每个3D点表示为从多个视角提取的特征集合,以融合点云表示的紧凑性和多视图表示的自然感知能力。
作者通过将每个点表示为从多个视角提取的特征集合,构建了Voint cloud这种新的表示形式。这种表示继承了点云表示的紧凑性和3D描述能力,并利用了多视图投影的丰富感知特征。
Voint cloud是由一组Voint组成的,每个Voint都是与视图相关的特征(视图特征),对应于3D点云中的相同点。每个Voint中的视图特征的数量可能会有所不同。
Voint cloud继承了显式3D点云的特性,这有助于学习适用于各种视觉任务(如点云分类和分割)的Voint表示。为了在新的Voint空间上应用深度学习,定义了一些基本操作,如池化和卷积。这些操作允许在Voint云上进行特征提取和处理。
作者通过定义在Voint级别的池化和卷积操作,构建了Voint neural network (VointNet ),并利用该网络在Voint空间学习表示。
通过定义在Voint级别的池化和卷积操作,作者设计了VointNet 模型,可以学习和处理Voint cloud表示。通过这种方式,作者旨在提高3D视觉任务的性能,并在标准基准测试中展示出最先进的性能。
基于这些操作,提出了一种实用方法来构建Voint神经网络,称为VointNet 。VointNet 接受Voint cloud作为输入,并输出用于3D点云处理的点云特征。并展示了学习这种Voint cloud表示如何在ScanObjectNN和ShapeNet等数据集上产生良好的结果。通过VointNet 能够有效地处理和分析3D点云数据,并为各种任务提供丰富的特征表示。
该方法的好处:
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
